―『孫子』十三篇を事例として―

はじめに―N-gramモデルとは―
筆者はここ数年、「N-gramモデル」という自然言語処理の分野で使われてきた方法を用いて、先秦文献の成書時期を探る試みに取り組んできた。
N-gramモデルは、情報理論の創始者として名高いクロード・エルウッド・シャノンが提唱した確率統計的な言語処理の手法で、N-gram自体は「あるテキスト全体を前から順に任意のN個の文字列または単語の組み合わせで分割したもの」を意味する。N個を単位とする文字列または単語の組み合わせを「共起」と呼び、N個の数(gram数)に応じてそれぞれ「1gram,2gram,3gram…」と呼び(二文字単位ならば2gramである)、テキスト全体での任意の「共起」を集計した結果は「共起頻度」と呼ばれる。
これだけだと意味が分からないかもしれないので、具体例を挙げてみよう。
例えば「あいうあい」という文字列があるとしよう。これを2gramで先頭から一文字づつずらして切り分けると「あい」「いう」「うあ」「あい」という結果が得られる。「あい」「いう」のような二文字単位とする組み合わせが「共起」であり、また「共起頻度」は「あい」が2、残りの「いう」「うあ」がそれぞれ1となる。
N-gramモデルを利用した漢字文献の分析については、本センター発行の『明日の東洋学』第8号掲載の石井公成氏の論攷や、筆者の関係論攷を参照いただきたい。本稿では、N-gramモデルと統計学の多変量解析の手法であるクラスター分析を用いて、先秦文献の成書時期を探る試みの一端を、『孫子』十三篇を対象として紹介してみることにしたい。
『孫子』十三篇の成書時期に関する研究史
『孫子』十三篇については、『史記』が春秋末期の呉の孫武自著説以降、作者に関して様々な説が唱えられてきたが、20世紀になると文献学の発達により『孫子』十三篇は戦国期のものであるとする説が有力になった。しかし、一九七二年に銀雀山漢墓より所謂『孫臏兵法』竹簡が出土するとその様相は一変し、孫臏以前の春秋末〜戦国前半(前5世紀中頃〜前4世紀中頃)の成書とする説が優勢となり、『孫子』の中に春秋末期の軍事制度や軍事思想を探る試みも行われているのが現状である。
確かに、銀雀山漢墓竹簡の発見は大きな出来事である。しかし、出土竹簡中に「孫氏之道」と孫武・孫臏を一体化した孫氏学派の存在を伺わせる記事が見られ、そもそも孫子・孫臏の二つに銀雀山漢墓竹簡の孫氏関係資料を分けてしまう事について、当初から金谷治氏等によりそれに対する疑義が出されていたが、現在に至るまで両兵書を分割して論ずる事は当然視されている。
しかし、『孫子』に使用される言葉について他の諸子書での使用状況を調べると、「『孫子』の成書は少なくとも戦国前半」という通念に対し、これに疑問を呈す用例がいくつも見つかるのである。
例えば、『孫子』始計篇冒頭の文章は「孫子曰。兵者。國之大事。死生之地。存亡之道。不可不察也。」だが、「兵者。國之大事。」は『春秋左氏伝』成公十三年「國之大事。在祀與戎。」とよく似ており、戦争を「戎」と表記する『左伝』の方が『孫子』より古い印象さえ受ける。また、文末の「不可不察」もまた、『墨子』『呂氏春秋』『荘子』『荀子』『韓非子』などの前3世紀に成書が降る文献で頻用される語法である。しかも『孫子』では、「不可不察」が始計篇意外にも九變・地形・九地篇で使用されている。この結果からすれば、『孫子』全体の成書が前3世紀に降る可能性も指摘できるのである。
このように、成書時期が不明な文献に対し、そこで使用される個々の言葉を成書時期の明らかな他の文献と比較する事によって成書時期を推定する手法は、非常に有効な手法である。通常この手法では、助字や特定の言葉・表現などをキーワードとして比較するのだが、この場合キーワードの選択が非常に重要となる事は言うまでもない。理想としては全ての言葉(文字)を対象として比較すればよいのだが、手作業でこれをするとなると大変な労力がかかり、集計の漏れや計算ミスをする可能性が避けられない。
そこで、本論では全ての言葉の用例を網羅的に集計するために、テキストを機械的に先頭から分割するN-gramモデルを利用し、またN-gramモデルで得られた個々の言葉(共起)の集計結果(共起頻度)を比較する方法として、統計学の多変量解析の手法として知られるクラスター分析を利用する事にした。
N-gramモデルを利用した『孫子』十三篇の分析
ここでは、以下の方法で分析を行った。
| 1. | まず『孫子』『論語』『左伝』『孟子』『墨子』(十論のみ)『荘子』『荀子』(勧学篇第一〜彊国篇第十七まで)『管子』(牧民篇第一〜幼官図第九まで)を対象として二文字単位(2-gram)で共起頻度を集計した。『孫子』以外の文献の選択理由は、成書時期が前4世紀以前のもの(『論語』『左伝』『孟子』)と前3世紀のもの(『墨子』『荘子』『荀子』『管子』)とに大きく二つに分ける事が出来るというのにある。 |
| 2. | 次にその中から他の諸子書で使用される共起のうち、『孫子』で使用されていないものについては、全て無用のデータであるため分析対象から外した(データを削除)。 |
| 3. | 更に各文献の総文字数に起因するデータの偏りを減らすために、各共起頻度を正規化したもの(各文献の共起頻度の平均を0、分散を1とする)を統計解析用データとして用意した。(2)(3)のデータの整理にはExcelを使用した。 |
| 4. | (3)で得られたデータを対象にクラスター分析を行った。クラスター分析の手法にはいくつかあるが、本論ではk-means法(初めから特定の数のクラスターが判明しているときに、使用する方法)で二つのクラスター(グループ)に分けたとき(この場合、前4世紀以前と前3世紀とがそれぞれ一つのクラスターを形成する)に、『孫子』がどちらのクラスターに属するかで、より可能性の高い成書時期を明らかにするためである。クラスター分析には、統計用ソフトとして著名なstatisticaを使用した。
|
- 共起頻度のデータ(上位1〜5位まで)
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
- 正規化したデータ
|
以下の表が、k-means法による距離とクラスターの出力結果である。
|
||||||||||||||||||||||||||||
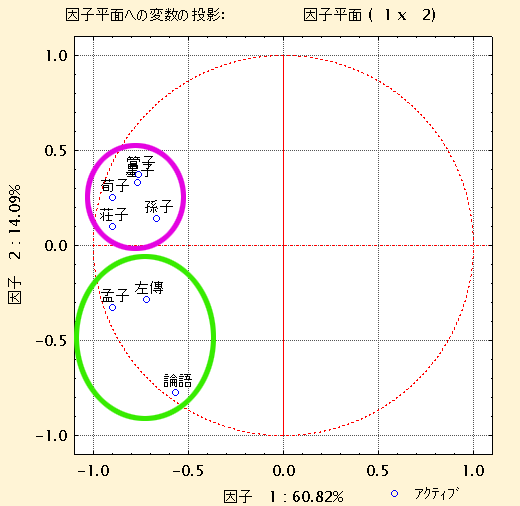
表を見れば一目瞭然だが、『孫子』は第2クラスター、即ち前3世紀成書の諸子書と同一のクラスターに含まれている。これを他の統計的手法、例えば主成分分析で測定しても、『孫子』は前3世紀と同グループに含まれる。従って、現行『孫子』十三篇で使用される言葉の他の諸子書での使用状況からすると、その成書時期は前3世紀に降る可能性が高いと言える。
おわりに変えて
本手法では、従来では難しかったデータ全てを対象に分析するという点に特徴がある。実際にはたまたま古い言葉を引用して作成されていたり、その言葉が後世流行したりした場合、クラスターもそれに引きずられる可能性があるため、単純にはクラスター分析の結果を受け入れる事は出来ない。また、単純に一書丸ごとを分析してしまっては、重層的な成書過程を持つ先秦文献の成書を明らかにする事は難しいだろう。
しかし、少なくとも当該クラスターに含まれた理由は個々の文献に立ち入って分析すれば判明するはずであり、その上でクラスター分析の結果を受け入れ・訂正の判断を下せばよい。従って、本論で採用した手法は、文献の学派・時代・地域に関わる見解の「たたき台」を提示ためには便利な方法と言えるだろう。
山田 崇仁(やまだ たかひと)
- 独立行政法人日本学術振興会特別研究員、立命館大学・聖泉大学非常勤講師
- 近著:「『孟子』の成書時期について―N-gramと統計的手法を利用した分析―」『立命館東洋史学』第27号 2004。「中国戦国期の語彙量について―N-gramとユールのK特性値を利用した分析―」『漢字文献情報処理研究』第5号 2004 好文出版。
- Webサイト「睡人亭」:http://www.shuiren.org/